Training Normalizing Flows¤
In this notebook, we use the API in flowMC to train two different normalizing flow networks to approximate a simple test distribution. The API is built on top of the companion libraries of JAX for deep learning, flax and optax.
In typical applications of flowMC to obtain samples from a given posterior distribution you will not need to interact with this level of the API, the training will be directly handled within the sampling. However you will need to choose the normalizing flow model and this tutorial exemplifies the abilities of the two models currently available in the package.
We train both a RealNVP flow from [Dinh et al. 2016] and a more complex normalizing flow model, the rational quadratic spline model [Durkan et al. 2019].
import jax
import jax.numpy as jnp # JAX NumPy
import optax # Optimizers
import equinox as eqx # Equinox
from flowMC.resource.model.nf_model.realNVP import RealNVP
from flowMC.resource.model.nf_model.rqSpline import MaskedCouplingRQSpline
We will use make_moons from scikit-learn to create a toy dataset in 2-dimensions.
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
data = jnp.array(make_moons(n_samples=100000, noise=0.05)[0])
plt.scatter(data[:, 0], data[:, 1], s=0.5, alpha=0.5, label="data")
plt.legend()
plt.show()
RealNVPs¤
We first use the RealNVP model to fit the data. We need to specify:
- n_layers: the number of coupling layers.
- n_hidden: the width of the hidden layers in the 1-hidden layer MLPs for learning the scales and translations in the affine coupling layers.
Inflating these numbers provides more flexibility to the normalizing flow, yet at the cost of increasing the computational budget.
# Model parameters
n_feature = 2
n_layers = 10
n_hidden = 100
key, subkey = jax.random.split(jax.random.key(0), 2)
model = RealNVP(
n_feature,
n_layers,
n_hidden,
subkey,
data_mean=jnp.mean(data, axis=0),
data_cov=jnp.cov(data.T),
)
jax.vmap(model.__call__)(data)
(Array([[-0.99613 , -0.10127474],
[-0.14790912, 1.6296724 ],
[ 3.0793257 , -1.157111 ],
...,
[ 0.67037183, 0.05505186],
[ 2.5246344 , -1.467852 ],
[-1.0591872 , 0.1318307 ]], dtype=float32),
Array([1.3785942, 1.3574398, 1.3711026, ..., 1.3693422, 1.3767755,
1.3767034], dtype=float32))
Next, we initialize a train_state following flax logic and an optax optimizer beforw lanching the training.
# Optimization parameters
num_epochs = 100
batch_size = 10000
learning_rate = 0.001
momentum = 0.9
optim = optax.adam(learning_rate)
state = optim.init(eqx.filter(model, eqx.is_inexact_array))
key, subkey = jax.random.split(key)
key, model, state, loss = model.train(
key, data, optim, state, num_epochs, batch_size, verbose=True
)
Training NF, current loss: 1.364: 100%|██████████| 100/100 [00:08<00:00, 12.35it/s]
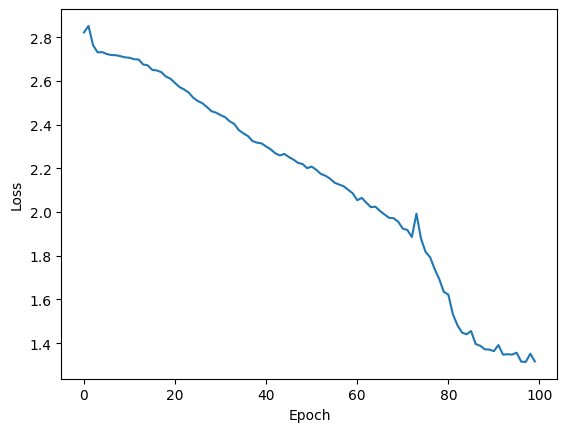
plt.plot(loss)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show()
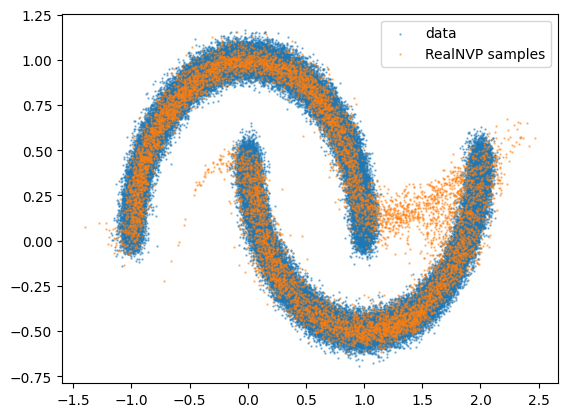
Finally we can visualize what the flow has learned by comparing the data distribution to the distribution of samples from the flow.
key, subkey = jax.random.split(key, 2)
nf_samples = model.sample(subkey, 10000)
plt.figure()
plt.scatter(data[:, 0], data[:, 1], s=0.5, alpha=0.5, label="data")
plt.scatter(
nf_samples[:, 0], nf_samples[:, 1], s=0.5, alpha=0.5, label="RealNVP samples"
)
plt.legend()
plt.show()
RQSplines¤
The second type of flows available are the RQSpline. These models are also based on coupling layers, however they allow for transformation more expressive than affine, namely splines of quotients of quadratic functions. Here the parameters are:
- n_layers: the number of coupling layers.
- n_hidden: the list of widths of the hidden layers MLPs for learning the polynomial coefficients.
- n_bins: the number of bins for the spline decompositions.
As previsouly, the bigger these numbers the more flexibility to the normalizing flow and higher is the computational cost of one training iteration. While RQSplines are generally more computationally demanding per training step than RealNVPs, there can be a favorable trade-off in selecting this more sophisticated model as it may require less iterations to converge to a satisfactory solution.
# Model parameters
n_feature = 2
n_layers = 8
n_hiddens = [64, 64]
n_bins = 8
key, subkey = jax.random.split(jax.random.key(1))
model = MaskedCouplingRQSpline(
n_feature,
n_layers,
n_hiddens,
n_bins,
subkey,
data_cov=jnp.cov(data.T),
data_mean=jnp.mean(data, axis=0),
)
num_epochs = 100
batch_size = 10000
learning_rate = 0.001
momentum = 0.9
optim = optax.adam(learning_rate)
state = optim.init(eqx.filter(model, eqx.is_inexact_array))
key, subkey = jax.random.split(key)
key, model, state, loss = model.train(
key, data, optim, state, num_epochs, batch_size, verbose=True
)
Training NF, current loss: 1.196: 100%|██████████| 100/100 [00:17<00:00, 5.60it/s]
plt.plot(loss)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show()
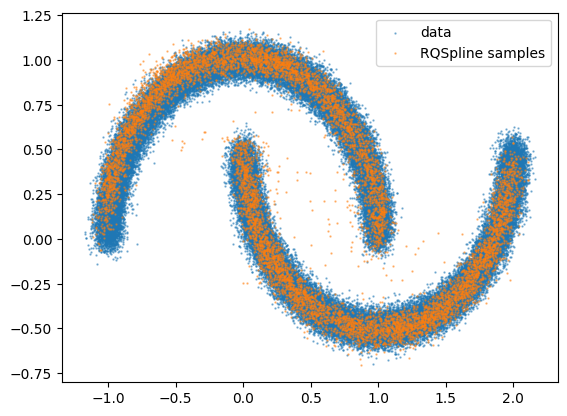
key, subkey = jax.random.split(key, 2)
nf_samples = model.sample(subkey, 10000)
plt.figure()
plt.scatter(data[:, 0], data[:, 1], s=0.5, alpha=0.5, label="data")
plt.scatter(
nf_samples[:, 0], nf_samples[:, 1], s=0.5, alpha=0.5, label="RQSpline samples"
)
plt.legend()
plt.show()
Here below is an example to show how the training model interact with the top level resource-strategy API
from flowMC.strategy.train_model import TrainModel
from flowMC.resource.optimizer import Optimizer
from flowMC.resource.buffers import Buffer
rng_key, rng_subkey = jax.random.split(jax.random.key(0), 2)
model = MaskedCouplingRQSpline(
n_feature,
n_layers,
n_hiddens,
n_bins,
subkey,
data_cov=jnp.cov(data.T),
data_mean=jnp.mean(data, axis=0),
)
n_chains = 10
n_steps = 100
n_dims = 2
num_epochs = 100
batch_size = 10000
learning_rate = 0.001
momentum = 0.9
test_data = Buffer("test_data", (n_chains, data.shape[0] // n_chains, n_dims), 0)
test_data.update_buffer(
data.reshape(n_chains, data.shape[0] // n_chains, n_dims),
data.shape[0] // n_chains,
)
optimizer = Optimizer(model)
resources = {
"test_data": test_data,
"optimizer": optimizer,
"model": model,
}
strategy = TrainModel(
"model",
"test_data",
"optimizer",
n_epochs=100,
batch_size=batch_size,
n_max_examples=100000,
verbose=True,
)
key = jax.random.key(42)
print(resources["model"].data_mean, resources["model"].data_cov)
key, resources, positions = strategy(
key,
resources,
jax.random.normal(key, shape=(n_chains, n_dims)),
{},
)
[0.50011855 0.24977292] [[ 0.752463 -0.19324097]
[-0.19324097 0.24699372]]
flowMC.strategy.train_model - INFO - Training model model
flowMC.strategy.train_model - DEBUG - Training data shape: (100000, 2)
flowMC.strategy.train_model - DEBUG - Number of epochs: 100
flowMC.strategy.train_model - DEBUG - Batch size: 10000
Training NF, current loss: 1.336: 100%|██████████| 100/100 [00:12<00:00, 7.98it/s]
flowMC.strategy.train_model - INFO - Completed training model - Final loss: 1.257569
flowMC.strategy.train_model - DEBUG - Loss values: min=1.223082, max=2.802106
output_samples = resources["model"].sample(jax.random.key(42), 10000)
plt.scatter(output_samples[:, 0], output_samples[:, 1], s=0.5, alpha=0.5, label="data")
plt.show()